
According to Gartner Forecasts, the worldwide end-user spending on public cloud services is forecast to grow by 23% in 2021 to the total $332 billion – up from $270 billion in 2020.
Kafka is no different in that matter. Organizations all over the world are using Kafka as their main stream-processing platform for collecting, processing, and analyzing data at scale. As organizations evolve and grow, data rates grow too, as does the consequent cloud cost.
So what can we do? Is there any low-hanging fruits we can implement in order to cut some costs?
Here are few tips and KIPs (Kafka improvement proposals) that might help!
Disclaimer
This post is not going to cover the managed services method of cutting costs.
In some use cases, managed services like Confluent Cloud might do the trick.
For more information on that, you can refer to Cost Effective page on Confluent website.
Before we get started, we need to understand some basics.
What are we paying for?
I can try to list all the components that we are paying for when using the various cloud providers out there, but I won’t be able to do it as well as Gwen Shapira in her post “The Cost of Apache Kafka: An Engineer’s Guide to Pricing Out DIY Operations” –
Start with some fairly obvious and easy-to-quantify expenses
If you are going to run Kafka on AWS, you’ll need to pay for EC2 machines to run your brokers. If you are using a Kubernetes service like EKS, you pay for nodes and for the service itself (Kubernetes masters). Most relevant EC2 types are EBS store only and Kubernetes only supports EBS as a first-class disk option, which means you need to pay for EBS root volume in addition to the EBS data volume. Don’t forget that until KIP-500 is merged, Kafka is not just brokers — we need to run Apache ZooKeeper too, adding three or five nodes and their storage to the calculation. The way we run Kafka is behind a load balancer (acting partially as a NAT layer), and since each broker needs to be addressed individually, you’ll need to pay for the “bootstrap” route and a route for each broker.
All these are fixed costs that you pay without sending a single byte to Kafka.
On top of this, there are network costs. Getting data into EC2 costs money, and depending on your network setup (VPC, private link, or public internet), you may need to pay both when sending and receiving data. If you replicate data between zones or regions, make sure you account for those costs too. And if you are routing traffic through ELBs, you will pay extra for this traffic. Don’t forget to account for both ingress and egress, and keep in mind that with Kafka, you typically read 3–5 times as much as you write.
Now we are running the software, ingesting data, storing it, and reading it. We’re almost done. You need to monitor Kafka, right? Make sure you account for monitoring (Kafka has many important metrics)—either with a service or self-hosted, and you’ll need a way to collect logs and search them as well. These can end up being the most expensive parts of the system, especially if you have many partitions, which increases the number of metrics significantly.
I highlighted the main points from the post, and there are other components from the Kafka eco-system that are not directly mentioned, like Schema Registry, Connect workers, as well as tools like CMAK or Cruise-Control, but it will be applicable to the same three factors-
Machines, Storage, and Network.
While there are more factors that are much harder to measure, like employee salaries, down-times, and even dealing with interrupts (aka – the work that must be done to maintain the system in a functional state), those are the main factors that we pay for when using a cloud provider.
What can we do?
Beside some basic concepts that are applicable to almost every distributed system, over time, Kafka’s committers introduced a few KIPs and features that directly or indirectly affect Kafka’s TCO.
But we will still start with the obvious ones –
Are you using the right instance types?
There are plenty of instance types to choose from on AWS (you can use the same ideas on other cloud providers of course).
Kafka can run easily and without any apparent problems on inexpensive commodity hardware, and if you will Google the recommended instance types for a production-grade Kafka cluster, you would find r4, d2 or even c5 combined with GP2/3 or IO2 storage as the broad recommendation.
Each one has its own pros and cons, and you probably need to find the right one for you based on various tradeoffs—a longer time-to-recover (HDD disks), storage-to-dollar ratio, network throughput, and even EBS performance degradations in extreme circumstances.
But over time, i3 and i3en machines were added to that list, and based on my experience, they are by far the most recommended instance types based on ROI for large-scale deployments, even if you are taking into consideration the operational overhead of using ephemeral drives.
i3 and i3en provide better performance on an endless amount of benchmarks when using Kafka, and leverage the ephemeral drive advantages (10gbps disk bandwidth vs 875mbps on EBS-optimized C-class instances).
This great post by ScyllaDB examines how using i3en machines are much cheaper on systems where the main limiting factor is storage capacity (more on that later) –
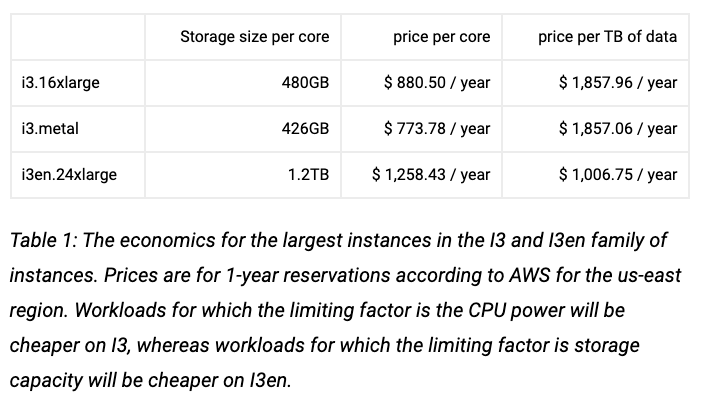
As the first step of cost reduction, you will need to re-evaluate your instance type decision: Is your cluster saturated? In what condition? Are there other instance types that might fit better than the one you chose when you first created the cluster? Does the mixture of EBS-optimized instances with GP2/3 or IO2 drives really cost less than i3 or i3en machines and their advantages?
If you are not familiar with this tool, you should be.
Update for 2022: Today, the maturity of Graviton2 instances has proven itself. You might consider using these instance families as well! – It’s already running successfully in production in dozen of companies. You can start here.
As for non-graviton instances, AWS announced the new i4i instance family, which has already been tested by ScyllaDB and looks very promising (although, I’ll always recommend waiting a bit longer before migrating production clusters to new instance families).
Compression
Compression is not new in Kafka, and most of the users already know that you can choose between GZIP, Snappy and LZ4. But since KIP-110 was merged and added codec for Zstandard compression, it enabled a significant performance improvement, and a perfect way of reducing costs on networking.
Zstandard is a compression algorithm by Facebook; it aims for a smaller and faster data compression when compered to other compression algorithms.
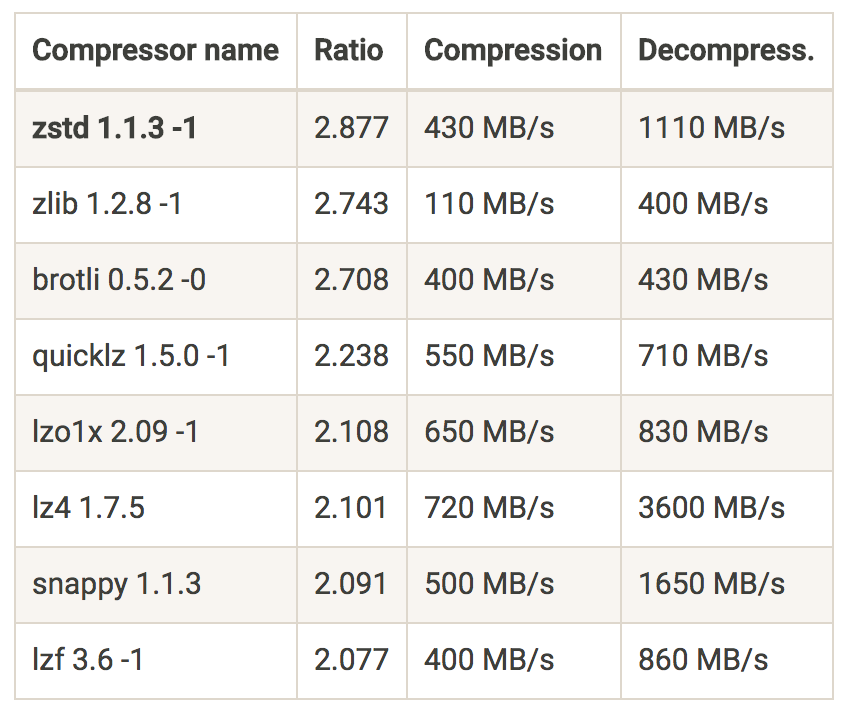
For example, using zstd (Zstandard), Shopify was able to get 4.28x compression ratio. Another great example on the impact that zstd can make is “Squeezing the firehose: getting the most from Kafka compression” from Cloudflare.
And how is that relate to cost reduction? At cost of slightly higher CPU usage on the producer side, you will get a much higher compression ratio and “squeeze” more information on the line.
Amplitude describes in their post that after switching to Zstandard, their bandwidth usage decreased threefold, saving them tens of thousands of dollars per month in data transfer costs just from the processing pipeline alone.
You are paying for data transfer costs as well, remember?
Fetch from closest replica
It is common to spin your clusters on few availability zones within the same AWS region for fault tolerance.
Unfortunately, it is impossible to coordinate the placement of the consumers to be perfectly aligned with the leader of the partition that they need to consume in order to avoid cross-zone traffic and costs. Enters KIP-392.
Enabling rack awareness is possible since KIP-36 back in 2015, and can be easily done by adding a single line to your configuration file:
broker.rack=<rack ID as string> # For example, AWS AZ IDBefore KIP-392 was implemented, this setting controlled only the replica placement (by treating the AZs as a rack). However, this KIP addresses exactly this gap, and allows you to leverage locality in order to reduce expensive cross-dc traffic.
Some clients have already implemented the change, and if your client is not yet supporting it, here’s an open source project for your weekend! 🙂
Cluster Balance
It might seem not that obvious, but your cluster imbalance might impact the cost of your cluster as well.
An imbalanced cluster might hurt the cluster performance, lead to brokers who are working harder than others, make response latency higher, and in certain circumstances lead to resource saturation on those brokers, and unnecessary capacity addition as a result.
Another risk you are exposed to with imbalanced clusters is higher MTTR after a broker failure (e.g., if that broker holds more partitions unnecessarily), and an even higher risk of data loss (imagine topics with a replication factor of 2, where one of the nodes struggle to start due to the high number of segments to load on startup).
Don’t let this relatively easy-to-do task become a money waste. You can use tools like CMAK, Kafka-Kit, or better yet, Cruise-Control, which allows you to automate these tasks based on multi goals (capacity violation, replica count violation, traffic distribution, etc.).
Fine tune your configuration – producer, brokers, consumers
Sounds obvious, huh?
But under the hood of your friendly Kafka clusters, there are tons of settings you can enable or change.
These settings can dramatically affect the way your cluster works: resource utilization, cluster availability, guarantee, latency, and many more.
For example, misbehave clients can impact your brokers resource utilization (CPU, disk, etc). Changing your clients batch.size and linger.ms (where business logic fits) can drop your cluster LoadAvg and CPU usage dramatically.
Message conversions introduce a processing overhead, since messages between the Kafka clients and brokers require conversion in order to be understood by both parties, leading to higher CPU usage. Upgrading your producers and consumers can solve this issue and free resources that were used unnecessarily for this task.
The number of examples are endless.
With the right fine tune, you can make your cluster work better, serve more, increase throughput, free up resources, and as a result avoid unnecessary capacity addition or even scale down your cluster to the right size for your needs.
It would be an impossible mission to read and process every line of the documentation, so you can start by reading one of the posts about tuning your clients and brokers. I would recommend the Strimzi series about it – Brokers, Producers, and Consumers.
The Future
Compression levels
As mention earlier, using one of the compression algorithms (preferably zstd) can give you great performance improvement and save you money on data transfer.
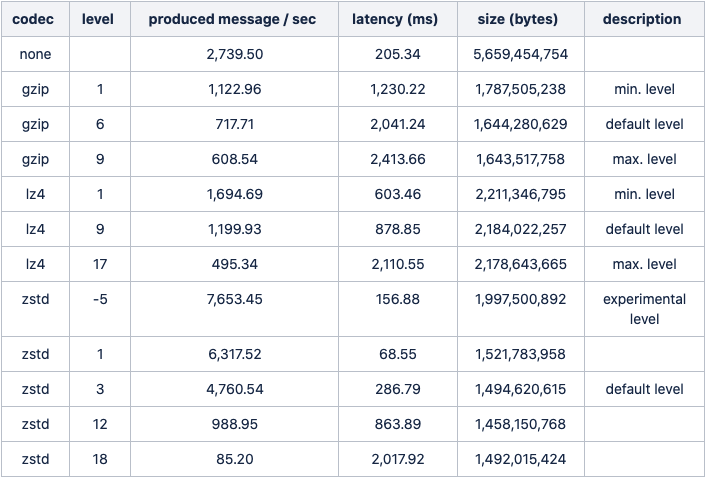
Dealing with compression introduce you to a new kind of trade-off that you need to decide on – CPU vs IO (the result compressed size). Most of the algorithms provide some kind of compressions level to choose from, which affects the amount of processing power required, and the result compresses dataset.

Until now, Kafka supported only the default compression level per codec. This aim is to be resolved on KIP-390 which will be shipped with Kafka 3.0.0.
After the KIP is implemented we will be able to add a single line to our configuration, and set the compression’s level higher (where it fits. Remember the resource overhead)
compression.type=gzip
compression.level=4 # NEW: Compression level to be used.The new feature tested against a real-world dataset (29218 JSON files with an average size of 55.25kb), and the result may vary based on the various coded, compression levels, and the resultant latency as you can see below
Tiered Storage
The total storage required on a cluster is proportional to the number of topics and partitions, the rate of messages, and most importantly the retention period. Each Kafka broker on a cluster typically has a large number of disks results in 10s of TBs on a single cluster. Kafka has become the main entry point of all of the data in organizations, allowing clients not only consume the recent events, but also older data based on the topic retention.
It’s likely that more brokers or disks will be added, just to be able to hold more data on your clusters based on your client’s needs.
Another common pattern is to split your data pipeline into smaller clusters, and set a higher retention period on the upstream cluster for data recovery in case of a failure. Using this method, you will be able to “stop” the pipeline completely, fix the bug down the pipeline, and then stream back all the “missing” events without losing any data on the way.
Both cases require you to add capacity to your clusters, and frequently, you are also adding needless memory and CPUs to the cluster, making overall storage cost less efficient compared to storing the older data in external storage. A larger cluster with more nodes also adds to the complexity of deployment and increases the operational costs.
To solve this problem, among others, KIP-405 Tiered Storage was made.
Using Tiered Storage, Kafka clusters are configured with two tiers of storage: local and remote. The local tier remains the same as it is today—local disks—while the new remote tier uses external storage layers such as AWS S3 or HDFS to store the completed log segments, which is much cheaper than local disks.
You will be able to set multiple retention periods for each one of the tiers, so services that are more sensitive to latency and use real-time data are served from the local disks, while services that need the old data for backfilling, or to recover after an incident, can load weeks or even months from the external tier efficiently.
Besides the obvious cost saving on disks (~$0.08 per GB on gp3 vs. ~$0.023 on S3), you will be able to do more accurate capacity planning based on your service’s needs (mostly based on compute power, and not storage), scaling storage independently from memory and CPUs, and save expenditure on unnecessary brokers and disks.
A huge cost saving.
The recovery of your brokers will be much faster as they will need to load significantly less local data on startup.
Tiered Storage is already available on Confluent Platform 6.0.0, and will be added to the Kafka 3.0 release.
KIP-500: Kafka Needs No Keeper
Just in case you haven’t heard yet, from future releases, Kafka will remove its dependency on ZooKeeper for managing the cluster metadata, and moved to a Raft-based quorum.
This will not only provide a more scalable and robust way of managing metadata and simplify the deployment and configuration of Kafka (remove external component), but also remove the cost of the Zookeeper deployment.
As mentioned before, Kafka is not just brokers, we need to run three or five nodes for Zookeeper nodes, and beside the instances, you will need to add their storage and network to the cost calculation, and the operational overhead that is hard to measure like monitoring, alerting, upgrades, incidents, and attention.
Summary
There are plenty of ways to reduce your cloud cost. Some of them are low-hanging fruits that can be implemented in a few minutes, while others require a deeper understanding, trial, and error.
This post covered only a fraction of the ways to reduce costs, but more importantly, tried to highlight the fact that it’s important to understand what are we paying for when running Kafka on the cloud.
We need to realize that sometimes cloud costs can be more than meets the eye.



[…] A Practical Guide for Kafka Cost Reduction by Elad Leev […]
[…] https://leevs.dev/kafka-cost-reduction/ […]
[…] A Practical Guide for Kafka Cost Reduction […]
We’ve been actually focusing on how to reduce Kafka cluster costs on our own as well by just switching the unrelying JVM. We demostrated that we can improve the performance of Kafka (namely throughput) by quite some number which can be turned to handling the same workload with fewer nodes -> cost reduction. You might want to take a look at https://www.azul.com/blog/the-practical-roi-of-running-kafka-on-azul-platform-prime/
Disclaimer: I work for Azul 🙂