
In a data-driven world, data freshness is a major KPI for modern data teams. Fresh data is much more valuable, and leads to better and more accurate insights.
But not all systems were born equal, and when dealing with legacy systems – achieve that could be quite a challenge, and might involve some scalability issues? How can you transform it into a reactive component?
Let’s start with the basics –
Batch vs Streaming
There’s a well-known saying about distributed systems: because of the complexity they bring, you should only use them when absolutely necessary. In a way, the same goes for Data Streaming which is more complex compared to batch processing. In a batch system, we process known finite-size inputs. We can always fix a bug in our code, and replay the batch. But in a stream, we process unbounded datasets which have no beginning and end.
Having said that, from a business perspective, there are clear benefits from using streaming instead of batching as in many cases, a business event loses its value over time.
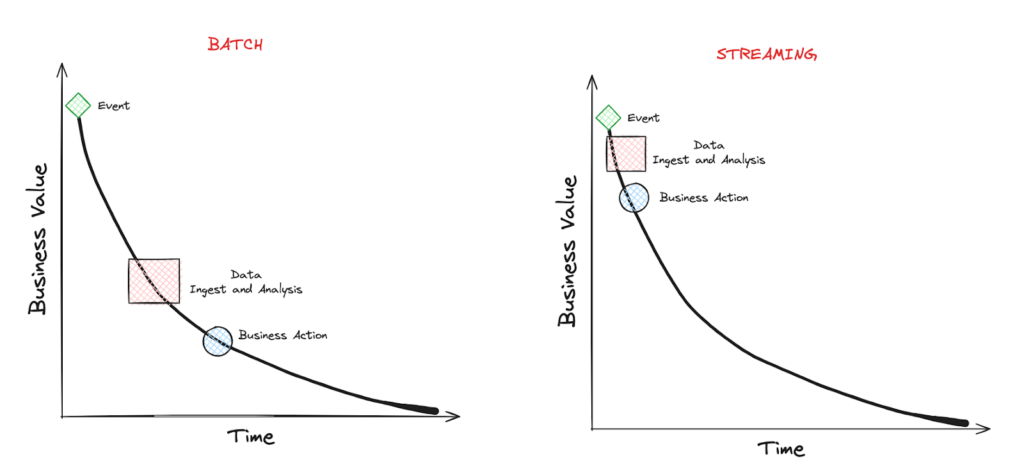
A good example of this is fraud detection services – Detecting fraudulent activities, such as credit card fraud or cybersecurity threats, requires immediate action to prevent further damage. Batch processing of transaction data introduces delays, during which fraudsters can continue their malicious activities. Streaming analytics enable real-time fraud detection systems to identify suspicious patterns as they occur, allowing for instant alerts and preventative measures.
The closer we can bring the action-taking to the business event, the better.
But what can you do if a legacy system is involved as part of the pipeline? A system that doesn’t “know” how to stream. In our case, an old ETL pipeline which is sourced from a legacy Oracle database.
Introducing, Change Data Capture
One of the ways to overcome this problem is by leveraging a common data pattern called “Change Data Capture” (CDC). It allows us to transform any static database into an event stream we can act upon.
The CDC process includes listening, identifying and tracking changes occurring in a database, and creating an event based on them.
CDC can be implemented using three main methods – Trigger based, Query based and Log based CDC.
A trigger-based CDC works by employing database triggers. In this approach, triggers are set up on tables within a database, and they are designed to activate automatically in response to specific data manipulation events, such as INSERT, UPDATE, or DELETE operations.
Query-based CDC, works by periodically querying the source database for any modifications. It is mainly used when direct modification of the source database is not feasible.
The last, and most efficient one is the log-based CDC. This approach leverages database transaction logs to capture and track changes made to data in a source database. This approach provides a near-real-time and efficient way to identify modifications, additions, or deletions without putting a significant load on the source database.
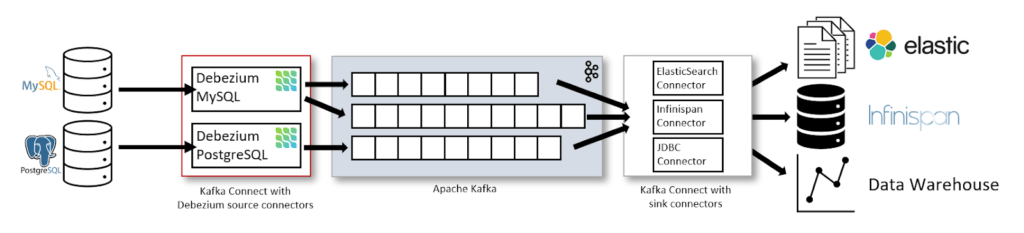
Debezium
When dealing with CDC and databases, the most common tool for the job is Debezium.
“Debezium is a set of distributed services that capture row-level changes in your databases so that your applications can see and respond to those changes. Debezium records in a transaction log all row-level changes committed to each database table. Each application simply reads the transaction logs they’re interested in, and they see all of the events in the same order in which they occurred.”
Debezium documentation
Debezium is actively maintained and supports the most common databases in the world – MySQL, MongoDB, PostgreSQL, Oracle, Spanner, and more.
Although you can run Debezium as a standalone Debezium Server or inside your JVM-based code using Debezium Engine, the most common practice is to deploy it as a Connector on top of a Kafka Connect cluster to leverage the benefits of the platform like orchestration, parallelism, failure handling, monitoring, and more.
Problem Statement
Our story begins with an old ETL pipeline which gets a dump of data every day, and later on loaded and processed on our data platform.
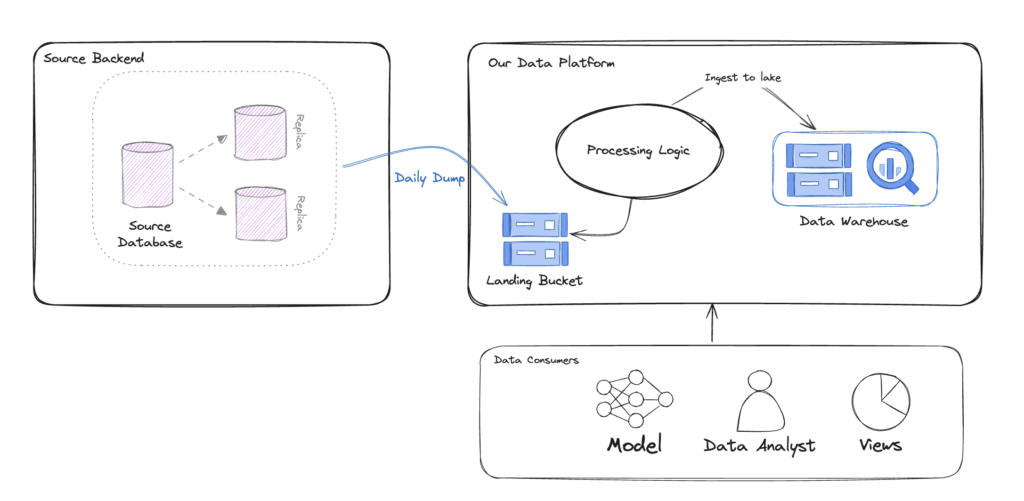
On the left side, we have the source backend which contains the Oracle database. Once a day, a new dump of the data is transferred to the landing bucket for processing.
On the right side, we have a service which holds the “Processing Logic”, that is, loading the data from the landing bucket, doing some data transformation and cleanup, making some business operations, and finally ingesting the result dataset to the Data Warehouse.
As data consumers, we have some ML Models, Data Analysts, and operational dashboards.
To begin with, we need to identify the problems with this solution:
As mentioned before, there are some obvious downsides to using such a method. As we deal with a daily batch of data, the freshness of our data is low.
Then, there are scalability issues and error handling. As companies continue to grows, the data volumes keep piling up to a point where the batches we process might take way too long to complete. It affects both the operation and business side – recovering from an error and re-processing a batch takes much longer over time, and our business decision-making is slower.
Now let’s make it better with Debezium!
The new architecture is fully based on Kafka, Kafka Connect and Debezium, to power (near) real-time ingestion to the Data Warehouse:
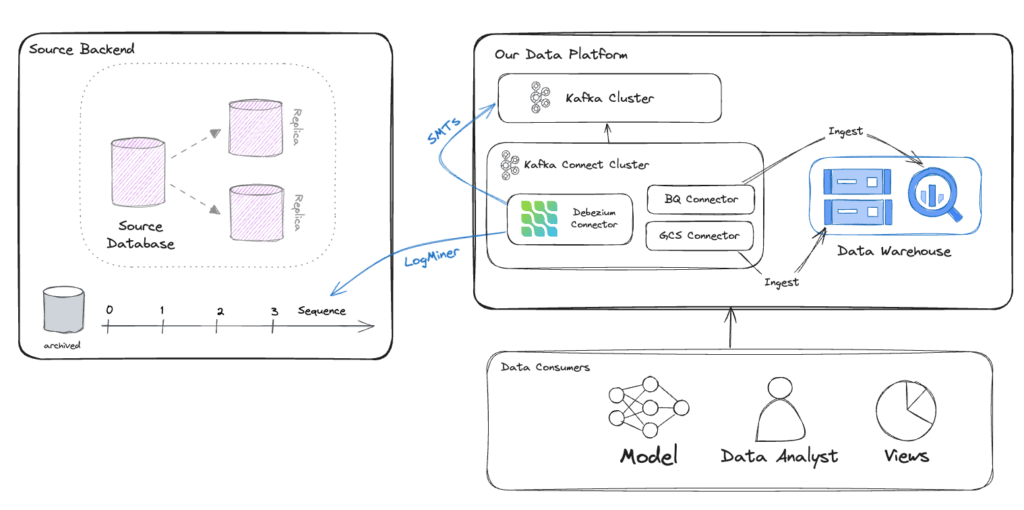
Instead of getting a daily dump of the data and processing it with an in-house service, we can leverage open source technologies which are developed and tested by thousands of engineers around the world.
In the new solution, the Debezium Oracle Connector is hosted on the Kafka Connect platform which simplifies the orchestration, scaling, error handling, and monitoring of such services. The connector is using Oracle LogMiner to query the archived and offline redo logs to capture the history of activity in the Oracle database.
Using Kafka Connect SMTs (more on that later), we can clean up and transform our CDC messages, and ingest them into Kafka.
To ingest the data into BigQuery and GCS, we can simply use another open-source Kafka connectors, which we can now scale independently.
The new pipeline is far more efficient, allows us to capture changes in real time, and reduces most of the complexity of the old pipeline. No service to maintain, battle-tested connectors and platform, a simple way to transform data, and the ability to independently scale each one of the components in the system.
Debezium Snapshot
On Oracle, the redo logs usually do not retain the full history of the database from the dawn of history. Consequently, the Debezium Oracle connector cannot access the entire database history from these logs. To allow the connector to create a baseline of the current database state, it takes an initial consistent snapshot of the database when it starts for the first time. This process can be controlled via a parameter called [snapshot.mode].
During the startup procedure, Debezium obtains a ROW SHARE MODE lock on each of the captured tables to prevent structural changes from occurring during the creation of the snapshot. Debezium holds the lock for only a short time.
Data Change Events
Once Debezium starts to capture all changed data (CREATE, UPDATE, DELETE, TRUNCATE), we will get the data change events to Kafka. Every data change event that the Oracle connector emits has a key and a value.
An expected CREATE event might look like the following:
{
"schema": {
"type": "struct",
"fields": [....],
"optional": false,
"name": "server1.DEBEZIUM.CUSTOMERS.Envelope"
},
"payload": {
"before": null,
"after": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "[email protected]"
},
"source": {
"version": "2.6.1.Final",
"name": "server1",
"ts_ms": 1520085154000,
"ts_us": 1520085154000000,
"ts_ns": 1520085154000000000,
"txId": "6.28.807",
"scn": "2122185",
"commit_scn": "2122185",
"rs_id": "001234.00012345.0124",
"ssn": 1,
"redo_thread": 1,
"user_name": "user",
"snapshot": false
},
"op": "c",
"ts_ms": 1532592105975,
"ts_us": 1532592105975741,
"ts_ns": 1532592105975741582
}
}In same cases, this is exactly what you would need – a stream of changes that an external system can consume. In this case, I don’t really need the extra information, and I simply want to replicate those events into Kafka while doing some basic transformations.
To do that, we can leverage Single Message Transformations.
Single Message Transformations
Single Message Transformations (SMTs) are applied to messages as they pass through Kafka Connect. SMTs modify incoming messages after a source connector generates them but before they are written to Kafka. They also transform outgoing messages before they are sent to a sink connector.
You can find more about SMTs in Debezium or Confluent documentation, but SMTs can be as easy as:
"transforms": "ExtractField",
"transforms.ExtractField.type": "org.apache.kafka.connect.transforms.ExtractField$Value",
"transforms.ExtractField.field": "id"The configuration snippet above shows how to use ExtractField to extract the field name "id"
Before: {"id": 42, "cost": 4000}
After: 42
In this case, we want to strip out most of the excess metadata, and only keep the value of the “after” event – as, the updated value, and some extra fields like ts_ms and scn for tracking.
To do so, we simply use the unwrap SMT:
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields: source.ts_ms,ts_ms,scnNow each one of our events in Kafka will consist of a key and a clean value.
Extend with a Custom SMT
Assuming one of our down-stream systems needs to make an aggregation based on the key of the messages, but it has only access to the message value. Can we fix it with SMT? Yes!
Unfortunately, there is no SMT which can take the message key and insert it as a field in the value, but SMTs are built the same way as the whole Kafka Connect platform – predefined interfaces which are easy to extend.
Introducing – KeyToField – SMT for Kafka Connect / Debezium.
With this custom SMT that I built, we can do exactly that – add the message key as a field. The SMT can also handle complex keys with multiple fields in it, using the transforms.keyToField.field.delimiter variable that will be used when concatenating the key fields.
A custom SMT can be as easy as a single Java file implementing the relevant methods.
@Override
public R apply(R record) {
if (record.valueSchema() == null) {
return applySchemaless(record);
} else {
return applyWithSchema(record);
}
}The apply method gets the record and perform the action based on the record schema (or schema-less).
We update the schema, put the new field as a string, and return the new record with the new schema and value:
private R applyWithSchema(R record) {
...
updatedSchema = makeUpdatedSchema(value.schema());
...
final String keyAsString = extractKeyAsString(record.keySchema(), record.key());
updatedValue.put(fieldName, keyAsString);
return record.newRecord(
record.topic(),
record.kafkaPartition(),
record.keySchema(),
record.key(),
updatedSchema,
updatedValue,
record.timestamp()
);
}
as simple as that.
Our final SMT configuration now looks like:
transforms: unwrap,insertKeyField
# Extract record
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields: source.ts_ms,ts_ms,scn
# Add key as field
transforms.insertKeyField.type: com.github.eladleev.kafka.connect.transform.keytofield.KeyToFieldTransform
transforms.insertKeyField.field.name: PKWith that, our pipeline is complete and relatively straightforward – Debezium generates the events from the source database, we transform the data using SMTs, ingest them to Kafka, and from there we have two connectors taking care of the ingestion to Big Query and GCS.
Conclusion
Dealing with legacy systems that rely on batch processing introducing a significant challenges in terms of data freshness, scalability, and timely business decision-making.
The transition to a modern data architecture leveraging Change Data Capture (CDC) with Debezium and Kafka addresses these issues effectively. By capturing and streaming real-time changes from the legacy Oracle database to Kafka, we significantly enhance data freshness and reduce latency. This new architecture facilitates near-real-time data processing and decision-making, enabling businesses to respond quicker.
In summary, the integration of Debezium and CDC into the data pipeline transforms a legacy batch processing system into a reactive, real-time data streaming architecture. This shift not only improves data freshness and scalability but also enhances the overall efficiency and responsiveness of the business, paving the way for more informed and timely decision-making.


